Chapter 2
Background
The context in which large Service Providers operate must be understood in order for this thesis’ objective to appear sensible.
2.1. Simplified Email System Overview
The design of large scale service provider e-mail systems is presented below. The network level protocol used to move mail between systems is the Simple Mail Transfer Protocol (SMTP), referenced in [2], with pertinent portions of its transactions defined later in this section.
2.2. Basic Functions
Stripped of all other features, an Email system has three functions as seen in figure 1. (1) it accepts mail on behalf of others, (2) it delivers mail to the messages’ intended recipients, and (3) provides disconnected operation by queuing messages where the recipient is not currently available for a later re-delivery attempt.
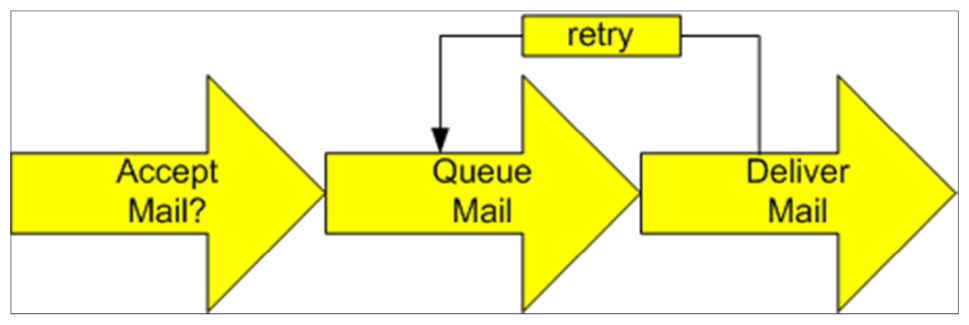
Figure 1: simple email system
2.3. Mail Flows
Email systems have two primary flows. Messages will take either an inbound or outbound path, depending on their origin & destination.
2.3.1. Inbound Flows
These messages are entering the mail system from other mail systems that are external to its administrative realm, or foreign to it. The foreign systems will have been directed to the local system by Domain Name System (DNS) Mail Exchanger (MX) records, or explicit administrator configured routing. Prior to accepting these messages, the local system will probably validate that the message’s recipients are valid mailboxes.
2.3.2. Outbound Flows
Messages sent from subscribers to mailboxes in foreign systems. It is the undesirable mail originating from the service provider’s subscribers that will impact the reputation of the outbound flows, which in turn will halt or delay delivery to foreign systems that consult and trust major Reputation Providers.
As previously mentioned, this thesis focuses on outbound flows.
2.3.3. Intelligence from Outbound Flows
Service providers have a considerable amount of intelligence relating to outbound mail flows that is not available for inbound flows. This is the information that will be used by the detection algorithm.
Key intelligence sources are:
- Availability of raw mail logs, and the ability to preserve these logs for baseline historical analysis.
- Ability to determine which customer sent a message: either the originating IP address, or the authenticated user name.
Using the above, service providers can exert far more fine-grained control on outbound flows than their inbound variant.
2.4. Simplified Email System Components
The opportunities, problems and constraints of a system are best understood by visualising its components.
Figure 2 enumerates the components of an email system that could be implemented by a service provider. Figure 3 overlays inbound and outbound mail flows over these components to demonstrate their areas of primary concern.
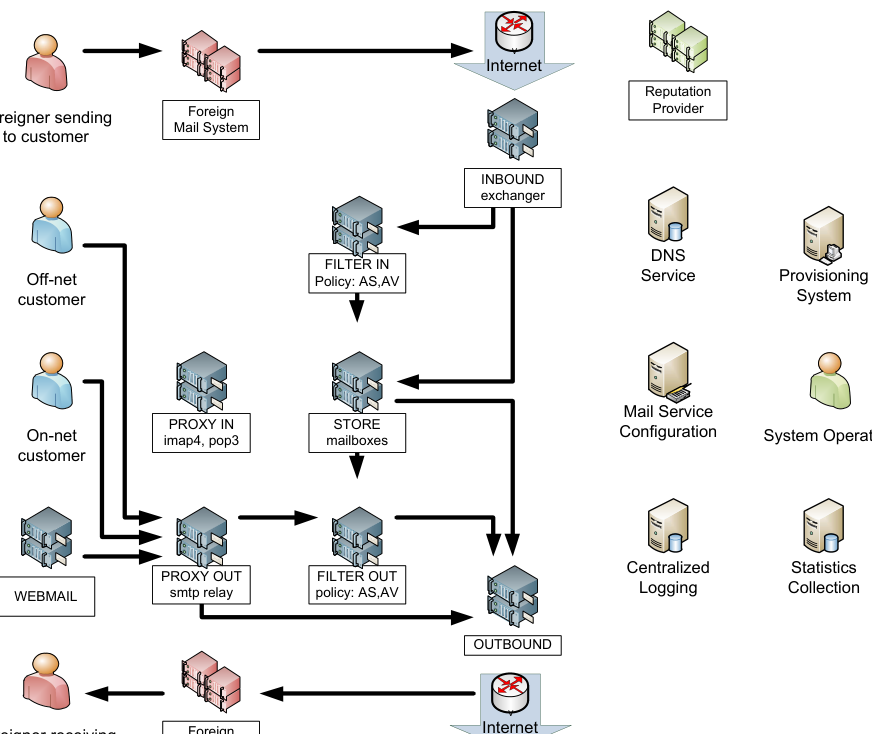
Figure 2: service provider Mail System Components and SMTP flows
2.4.1. Inbound Components
Referencing Figure 2, the components handling inbound mail flows are:
- Inbound Mail Exchangers, these receive mail from foreign systems
- Inbound Filtering, where anti-spam and anti-virus processing is applied by policy
- Mail Stores, contain the mailboxes that messages are delivered to
- Inbound Proxy, used to isolate the store from direct communication with customers. Proxies provide an abstraction layer to the mailboxes, which can be used to implement load balancing, reroute traffic during mail store maintenance, and provide the ability to rewrite or transform login credentials.
- Webmail, provides a web-based mail client. Often a prime target for attack or abuse, hence its isolation.
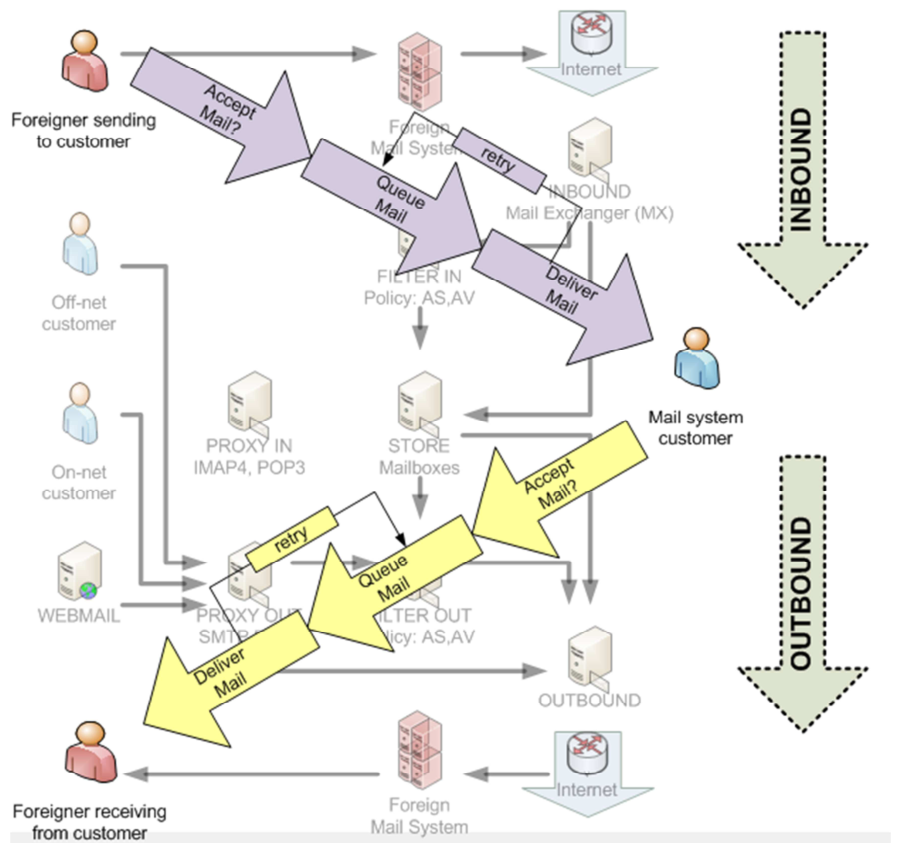
Figure 3: mail System Components and in/out flows
2.4.2. Outbound Components
Referencing Figure 2, the components handling outbound mail flows are:
- Outbound Proxy, the entry point for accepting messages that subscribers wish to deliver.
- Outbound Filtering, where outbound anti-spam and anti-virus is applied by policy.
- Outbound Queue system, the servers that will make the direct connection to the foreign destination servers. Also the only place in the mail system where messages should queue for delivery. Reducing queuing points reduces bottlenecks.
2.5. Large Scale introduces Complexity
Due to volume, the functions of a mailsystem are usually segregated to different servers. Redundant servers are deployed to keep the service available despite component failures.
This complicates mail flow analysis. The analysis provided in this thesis requires an aggregated view of the messages each subscriber submits to the outbound flows. The path a message takes through the email system will have to be rebuilt from information output to system logs as it traverses the many servers and daemons along its way.
2.6. Simple Mail Transport Protocol (SMTP)
This section provides a brief overview of the Simple Mail Transport Protocol (SMTP).
Proposed in 1982, RFC821 [3] standardized the client-server message exchange, and RFC822 [4] standardized the format of the messages. These have since been obsoleted by RFC’s 2821 [2] and 2822 [5], but these updates and clarifications have no material effect on this thesis.
2.6.1. SMTP Example
Figure 4 shows a complete SMTP transaction of a simple email being sent from a client (grey background) to a server (white background).
This paper focuses on actions at the envelope level, and SMTP response.
The actual message content, steps 3, 4, 5, 6 in Figure 4 is not of concern to this work. The structure of the message is dictated by RFC822 & 2822, the rest of the communication is RFC821/2821.
1. Connection $ telnet smtp.pacific.net.au 25
Trying 125.255.95.1...
Connected to mail-pacific.pacific.net.au.
Escape character is '^]'.
220 mailproxy2.pacific.net.au ESMTP Gday mate
helo netlog.net
250 mailproxy2.pacific.net.au
2. Envelope mail from: <martin_foster@pacific.net.au>
250 2.1.0 Ok
rcpt to: <sender@netlog.net>
250 2.1.5 Ok
3. Message data
354 End data with <CR><LF>.<CR><LF>
4. Message header Subject: This is my test message
From: "Some Sender" <fake@donottrust.net>
To: "Some Recipient" <sender@netlog.net>
5. Message body This is my message body.
6. Message end .
7. Server send 250 2.0.0 Ok: queued as F2F9727412
quit
221 2.0.0 Bye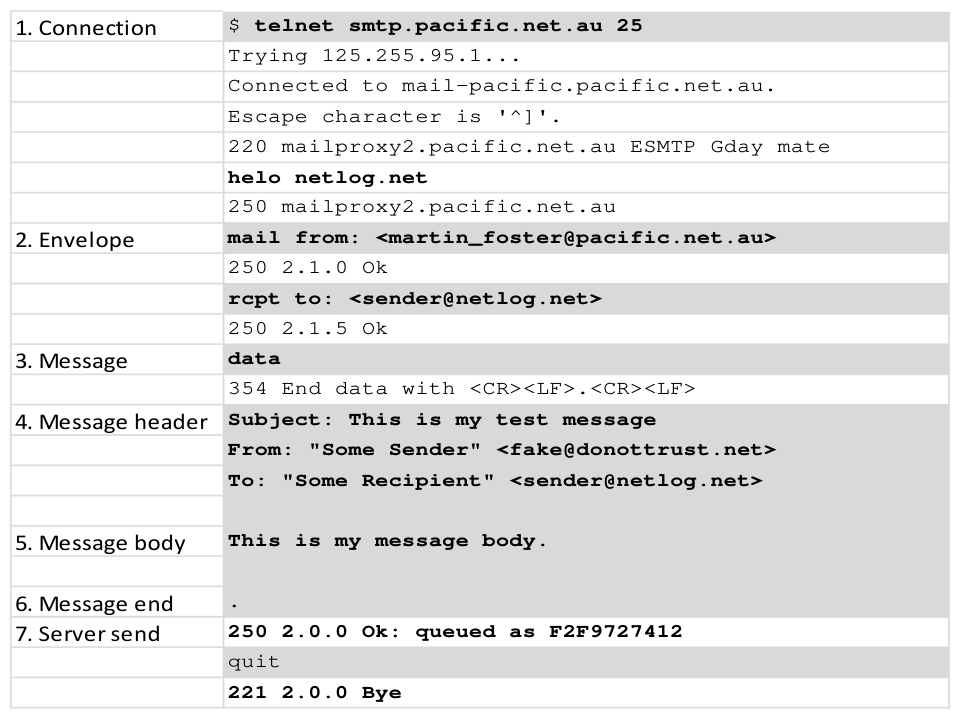
Figure 4: a SMTP transaction
2.6.2. SMTP Envelope
The example in Figure 4 shows that a message’s envelope can use different addressing than the message’s body. Note the difference between the envelope’s “mail from” and “rcpt to” instructions versus the message header’s To: & From: lines. This distinction often comes as a surprise to persons not familiar with e-mail’s protocols.
This is similar to paper mail – the envelope is responsible for the routing of the message, the message inside the envelope can contain whatever the sender wants it to. SMTP is the same, the envelope routes the message’s payload.
2.6.3. SMTP Reply Codes
In Figure 4 the server responds to client commands with a reply code in the 200-299 range. These replies are defined in RFC821/2821. For the purposes of this work, we want to know three broad response categories to a given command:
- Accepted: 200-299 range.
- Failed temporarily: 400-499 range. This means that something went wrong in processing the command, but that this failure may not be permanent. The sender is encouraged to try again later. For example, if the destination system is too busy or unavailable, the sending system is likely to return a temporary failure and retry delivery for given period of time. Systems consulting a RBL when deciding whether or not to accept inbound messages from a remote system will usually give a temporary failure response code if the sending IP Address is blocked. This provides a mechanism in which to advise the sender and the sender’s system’s administrators as to the reasons for the rejection.
- Failed permanently: 500-599 range. This means that something went wrong in processing the command, and that this command as given will not be accepted. This sort of response is often given to the “rcpt to” envelope command if the given recipient does not exist on the system.
2.6.4. SMTP Relay
E-mail systems should not relay mail for anyone on the Internet. Relaying is the act of accepting a message from a customer into a system’s outbound flows, and processing it for delivery. As previously mentioned, in large scale e-mail systems this processing often involves traversal of multiple servers, and queuing at the end of the chain for acceptance by foreign receivers.
Most systems use two criteria when deciding whether to relay. Either:
- Client network address, or “relay by IP address”. The client’s network address is looked up, if it belongs to addresses that the email server will relay for, it is accepted. This is usually used by ISPs providing relay services to customers on their network.
- Authentication. Covered in the next section, allows anyone with the proper credentials to send email.
Figure 4 demonstrates relay by IP address – no authentication is done.
For the purposes of managing spam, the developing trend is to move away from client network address checks to authentication. There are a few reasons for this.
With network based relaying, all messages from a source will be accepted. For administrators, this makes tracking the source of an exploited system more difficult as many computers could be in use behind a given address. If the one address is blocked while investigating a problem, many people are affected. There is also a series of exploits1 against networking equipment that allows attackers to exploit and use home & small business routers as SMTP relays that the downstream ISP email system will accept messages for. Relaying from authenticated accounts only and stopping the practice of relaying by IP address protects against this entire category of exploits.
With authentication, it is possible to provide unique credentials to each user. This makes identifying the exploited account and device a much simpler process. Authentication also enables users to relay via from their service provider’s e-mail system regardless of which network or physical location they are in; a bonus as the number of portable devices capable of sending email continues to increase.
2.6.5. SMTP Smarthost Servers
The term “smarthost” is used to describe servers that whose primary purpose is to relay mail for other servers in a multi-server system. They are effectively relays as described in the section above, and often deployed in places where direct outbound access to the internet is prohibited. The term is frequently used in datacentre or campus deployments.
2.6.6. SMTP Authorization and Encryption
The transaction in Figure 4 is very simple. At the establishment of the connection, other capabilities are often supported by the receiving server. Important ones are:
- Session authorization. A sender can be authorized to relay messages via e-mail systems that would otherwise reject them via authentication. The authentication mechanisms that a particular server supports can be queried by the client, the most common types being a username + password combination.
- Channel encryption. A SMTP transaction can be begun on a clear text channel, and subsequently cyphered with the STARTTLS command.
2.7. E-mail System Logs
The analysis of individual message’s flow through an e-mail system will be done via system logs. The generation of these logs is discussed here. The algorithms and analysis of the resulting logs is covered in Chapter 3.
2.7.1. Syslog Mechanism
The syslog (“system log”) mechanism and protocol allows software to generate event logs when a given action occurs. Syslog is provided by the Linux operating systems used in this work. The concepts carry to Microsoft Windows Events [6] which are similar in function but different in implementation and wire-level protocol.
Syslog provides means to state the facility for which a given message is generated, such a mailsystem, scheduler, kernel – and the severity of the message, from debugging, informational, warning, error and critical error.
The mechanisms and protocols are fully described in RFCs 3164 [7], and 5424 [8]. For the purposes of this work, note that informational messages are generated for most steps in the processing of an e-mail message.
In a large scale e-mail system, the logs from all participating servers tend to be aggregated at a centralized server (“loghost”) for analysis. The logs used by this work were collected from a loghost.
2.7.2. Outbound Flow Reconstructed from Logs
Figure 5 is the syslog representation of the SMTP transaction in Figure 4. Each line is numbered for quick reference.
This is the output provided by the Postfix Mail Transport Agent (MTA). There are other software packages available that can perform this task; if they are suitable for use in large scale e-mail systems they will log similar information.
In cross-referencing, the:
- client’s IP address is on line 1.
- the postfix daemon assigns a queue identifier (F2F9727412) on line 2. This allows the message to be traced in the receiving server – the queue identifier is returned to the client at the end of the transaction in Figure 4.
- message-id is generated in line 3, this identifier should be globally unique for the message’s entire delivery from sender to final recipient.
- envelope sender and recipient is given on lines 4 & 5.
The system logs also show that while the client’s message was accepted by a server called “mailproxy2”, it was subsequently handed off to another server “mailout1” within the mailsystem for queuing and delivery to the foreign recipient mailsystem. The postfix daemon running on “mailout1” issued a different queue identifier (16E444C817F) on line 6, but preserved the message-id on line 9.
1. 2009-05-22T02:02:59+00:00 mailproxy2.pacific.net.au postfix/smtpd[1081]: connect from
unknown[203.100.230.80]
2. 2009-05-22T02:02:59+00:00 mailproxy2.pacific.net.au postfix/smtpd[1081]: F2F9727412:
client=unknown[203.100.230.80]
3. 2009-05-22T02:03:00+00:00 mailproxy2.pacific.net.au postfix/cleanup[8950]:
F2F9727412: message-id=<4A157B2D.1030204@pacific.net.au>
4. 2009-05-22T02:03:00+00:00 mailproxy2.pacific.net.au postfix/qmgr[19788]: F2F9727412:
from=<martin_foster@pacific.net.au>, size=649, nrcpt=1 (queue active)
5. 2009-05-22T02:03:00+00:00 mailproxy2.pacific.net.au postfix/smtp[25662]: F2F9727412:
to=<sender@netlog.net>, relay=mailout.pacific.net.au[61.8.0.84]:25, delay=0.16,
delays=0.13/0/0/0.03, dsn=2.0.0, status=sent (250 2.0.0 Ok: queued as 16E444C817F)
6. 2009-05-22T02:03:00+00:00 mailout1.pacific.net.au postfix/smtpd[19765]: 16E444C817F:
client=mailproxy2.pacific.net.au[61.8.2.163]
7. 2009-05-22T02:03:00+00:00 mailproxy2.pacific.net.au postfix/qmgr[19788]: F2F9727412:
removed
8. 2009-05-22T02:03:00+00:00 mailproxy2.pacific.net.au postfix/smtpd[1081]: disconnect
from unknown[203.100.230.80]
9. 2009-05-22T02:03:00+00:00 mailout1.pacific.net.au postfix/cleanup[19769]:
16E444C817F: message-id=4A157B2D.1030204@pacific.net.au
10. 2009-05-22T02:03:00+00:00 mailout1.pacific.net.au postfix/qmgr[23206]: 16E444C817F:
from=<martin_foster@pacific.net.au>, size=869, nrcpt=1 (queue active)
11. 2009-05-22T02:03:10+00:00 mailout1.pacific.net.au postfix/smtp[19651]: 16E444C817F:
to=<sender@netlog.net>, relay=mx.netlog.net[208.78.102.55]:25, delay=11,
delays=0.03/0/8.5/2.1, dsn=2.0.0, status=sent (250 2.0.0 Ok: queued as 4CF462201AC)
12. 2009-05-22T02:03:10+00:00 mailout1.pacific.net.au postfix/qmgr[23206]: 16E444C817F:
removed
Figure 5: a SMTP transaction seen from system logs
2.8. Related Work
The author believes that using SMTP response codes to identify spammers in complex systems is a novel approach to managing the outbound spam volumes originating from an e-mail service provider’s infrastructure.
There is a substantial body of work in the field of spam mitigation, machine analysis of behaviour, and inter-system reputation.
2.8.1. Reputation
Third parties have long acted as reputation brokers for communication between two other organizations.
2.8.1.1. The Email Context
The effectiveness, design and evolution of DNS based Realtime Blocklists (RBLs) as e-mail reputation systems was covered in 2007 by Alperovitch, Judge, and Krasser [9].
RBLs list IP addresses known to have been the source of spam, or URL known to have been seen in the content of spam. Because of their binary spam/not-spam tagging behaviour, effective RBLs have to update cautiously in order to minimize false positives. This cautious update process has been heralded as their principal weakness. The advent of rapidly changing spam sending botnets documented in [10] was seen as the demise of RBLs [11].
In response to this criticism, some reputation providers have begun offering multiple data sets that have differing goals and update velocities. For example MAPS offers a long lived RBL+ high assurance list and a rapidly adapting QIL list [12].
The author has empirical data suggesting that RBLs continue to eliminate over 90% of inbound spam flows with very low false positive. Other parties have reported numbers in the 80% range when applied to botnets alone [13]. The actual efficiency of RBLs will vary based on mail system size, mail system age (the longer a system has been around, the better it is known to spammers), and the number of domains whose email is hosted by this system.
There exists many RBL providers, the most popular ones listing known spam sources are Spamhaus [14], MAPS [12], and SpamCop [15]. The most popular list of URLs placed in spam message content is SURBL [16].
The existence of these reputation providers and their continued relevance is the basis for this research in spam sender identification: to avoid impacting mail system users that exhibit “good” behaviour while stopping or penalizing the bad.
2.8.1.2. Outside the Email Context: P2P
Research in Peer to Peer (P2P) networks have proposed reputation based mechanisms to ignore or exclude nodes that are known to offer decoy files: files that are something else than what they claim to be. This is essentially the spam of the P2P world.
The Credence system described in [17] and [18] implements a reputation system similar to email RBL providers – peers are rated by the positive and negative endorsements of others.
2.8.2. Behaviour
This work will draw on prior research into the behaviour of spam networks, legitimate senders, and spam senders when attempting to classify subscribers.
2.8.2.1. Network Behaviour of Spam
In 2006 Ramachadran [13] then in 2007 Gansterer [19] investigated the network level behaviour of spam sending networks. While there is evidence that these networks are adapting to advances in detection mechanisms, this research provides a good baseline for identifying a “standard” botnet.
2.8.2.2. Network Behaviour of Spam: HVS versus LVS
In 2008 Pathak, Hu, and Mao [20] operated a selective e-mail relay server to gain an updated understanding of how spammers were using misconfigured e-mail servers to relay mail. Their work is important because it confirmed system and network operator observations that spammers appeared to be changing their behaviour.
Earlier, spammers were generally observed sending high volumes of spam to misconfigured or compromised relay systems as soon as they were discovered. The authors codified this behaviour as High-Volume Spammers (HVS). Spammers knew that a short window of opportunity existed to use the system before its administrators noticed the volume and reacted to it, or RBL operators noticed the volumes and listed the server as a source of spam.
What the authors observed is that more e-mail was being sent by Low-Volume Spammers (LVS). Instead of sending a mass volume of email through the relay over a short period of time, they would send a low volume of email from many different sources over an extended period of time – the goal being to avoid detection.
The authors also noted that some of the clients exhibiting LVS behaviour appeared to be working under the command of a centralized orchestrator: multiple members of a coordinated botnet.
2.8.2.3. Foreign System SMTP Reply Codes
The work done by Richard Clayton observing the logs of UK ISP Daemon Internet in 2004 [21] uses the same metric as this work does to determine the likelihood that a sender is a spammer: SMTP result codes provided by a foreign system during a delivery attempt. This topic is also discussed in this thesis in section 2.6.3. The difference with this work is in system complexity and volume.
Their work showed that a specific sender which exhibits a low overall rate of delivered messages is more likely to be a spammer. Spammers tend to use lists of email addresses with a higher percentage of invalid or no longer valid email addresses. These email addresses are usually rejected by the foreign system when a delivery attempt is made, with the rejection indicated within the SMTP protocol and logged to the system logs.
The service provider e-mail system described for Daemon Internet at the time used one type of server as a “smarthost” (see section 2.6.4) for relaying outgoing mail from customers. While there were many similarly configured system for redundancy, the path taken by messages in outbound flows was only one server “deep”, a simplification that greatly eases log analysis because a message’s traversal through the infrastructure does not have to be rebuilt from system logs to extract and correlate the source’s connection on one server to the response codes returned by the foreign e-mail system as seen on another server.
The last major difference is that in 2004, the majority of spam was delivered using High Volume Spam (HVS) whereas today the bulk is Low Volume Spam (LVS).
2.8.2.4. Behaviour of Email Users
An observed fact about email user behaviour is that people’s social networks tend to be reproduced in their email patterns.
In 2002, Pujol et al. [22] worked to identify social networks in generic transactions between agents. The research attempted to map peoples’ social circles by analysing who they communicated with, and how often. While this research was not originally applied to e-mail communications, there is reason to believe it would be applicable because all e-mail transactions contain the required sender and recipient information.
Columbia University’s Intrusion Detection System (IDS) lab’s Email Mining Toolkit (EMT) described in [23], [24], and [25] proposes and implements multiple mechanisms for abnormality detection in sender behaviour. Metrics track volume behaviours in time, the development of expected recipients by building maps of social networks (cliques), and the identification of changes as a result of exploitation or takeover by a malicious sending agent.
A subset of the EMT known as the Profiling Email Toolkit (PET) was implemented in [25] for real-time analysis. It was restricted to acting at the mail client endpoint, and not directly on a large scale distributed mail system.
2.8.3. Outbound Spam
The last category of related work focussed on mechanisms to reduce outbound spam without taking into account user behaviour. [26] Proposes three mechanisms that could be implemented by large scale e-mail service providers, all relate to imposing a cost – either financial or computational – on the sending of a message.
The problem with these proposals is that to be effective cost-based mechanisms need to be accepted by a large set of organizations exchanging email. So far this has not happened as there are: (1) too many objections to putting a cost on a resource that is currently seen as free or near-free, (2) no one can agree on who would regulate or collect a financial “postage” fee for sending a message, (3) cost based mechanisms are biased against developing economies that have less financial and computational resources, and (4) it is now assumed that spammers would easily absorb any computational cost by using their existing spam sending networks. The disagreement on financial cost and non-effect of a computational cost appears to have halted development of all mechanisms proposed by [26].
Footnotes
-
Limited formal research in this field, but it is a behaviour observed by ISPs. See http://technocrat.net/d/2008/1/12/33775/ ↩